
Когда кончатся данные
Стоит ли ожидать дефицита качественной информации для обучения ИИ-моделей
Запасы данных в мире для обучения языковых моделей исчерпаются в 2026–2030 годах, прогнозируют эксперты. Выходом из этой ситуации могут стать синтетические данные, созданные искусственным интеллектом (ИИ). Действительно ли информация, на основе которой обучаются нейросети, может закончиться и насколько будут эффективны синтетические данные – в материале RSpectr.
ОНИ ТОЧНО ЗАКОНЧАТСЯ?
Мировой запас общедоступных текстов, созданных человеком, составляет 300 трлн символов, подсчитал исследовательский институт Epoch AI. Также аналитики предположили, что объем информации для обучения больших языковых моделей (LLM) исчерпает себя до 2030 года. Созданные человеком высококачественные данные закончатся к 2028 году, предупреждают аналитики.
Однако ИИ-разработчики продолжают выпускать новые версии своих решений. Например, для обучения языковой модели типа GPT-3 потребовалось 570 ГБ текстовой информации.
Открытые и оцифрованные данные могут закончиться, однако в настоящее время существует множество различных медиаформатов, благодаря которым можно продолжать тренировать LLM-решения, рассказал RSpectr исполнительный директор Ассоциации больших данных (АБД) Алексей Нейман.
Эксперт добавил, что
в будущем будут разрабатываться специализированные LLM-решения, и речь пойдет о новых архитектурах и качественных характеристиках моделей
Epoch AI драматизирует ситуацию c запасами данных, полагают в АНО «Цифровая экономика». Новая информация создается с куда большей скоростью, чем потребляется моделями ИИ, прокомментировали RSpectr аналитики.
Однако существует и другая точка зрения. ИИ – это далеко и не всегда про гигантские наборы данных.
В конце июня 2024 года компания Google добавила в свой переводчик 100 новых языков, среди которых такие низкорепрезентированные языки, как башкирский, бурятский, чувашский, а другая компания с 2022 года ведет активные разработки решений для подобных языков в рамках проекта NLLB (No Language Left Behind), рассказала RSpectr руководитель отдела анализа данных и машинного обучения Naumen Татьяна Зобнина.
Однако ключевой проблемой является не просто отсутствие дополнительного объема данных. Речь идет о нехватке именно качественных и полезных текстов, согласился с прогнозами Epoch AI заместитель исполнительного директора по IT & Data Science Центра НТИ по большим данным МГУ имени М.В. Ломоносова Александр Бирюков. С появлением LLM люди все меньше создают оригинального контента, напомнил он RSpectr.
Также важно отметить, что данные не только добавляются, но и пропадают и корректируются, что усложняет задачу обучения, пояснил RSpectr руководитель «Лаборатории инноваций НОРБИТ» Дмитрий Демидов.
Эксперт подчеркнул, что
это может создать ситуацию, при которой ранняя ИИ-модель из 2025 года окажется более полезной, чем из 2030 года
РОДНАЯ РЕЧЬ
Но в исследовании Epoch AI речь идет исключительно о зарубежном опыте. Насколько нехватка качественного контента затронет русскоязычный сегмент?
В России имеется также ряд уникальных источников, которые могут быть использованы для обучения моделей. Это, например, не только данные из интернета, но и специализированные датасеты, создаваемые в рамках различных проектов и инициатив, рассказал в беседе с RSpectr директор по продуктам компании «Наносемантика» Григорий Шершуков.
Обучение LLM-решений зависит от языка, на котором созданы данные. Специфика англоязычных и русскоязычных текстов будет различаться. Понять, какой язык является «родным» для нейросети, легко. Она лучше понимает запросы, так как внутренние команды осуществляются на языке обучения. Как обстоят дела с качественными данными на русском языке?
По мнению Дмитрия Демидова, отечественные разработки опираются чаще всего на существующие модели с открытым исходным кодом.
Дмитрий Демидов, «НОРБИТ»:
– Их дообучают либо общими данными, либо данными конкретного домена для решения какой-то узконаправленной задачи. Дообучение на специализированном домене. Проще говоря, создание такой модели, которая очень хорошо разбирается в конкретной теме.
Алексей Нейман считает, что
русскоязычный оцифрованный контент закончится быстрее, чем англоязычный, так как его значительно меньше
«С этой точки зрения предобученные LLM-решения на английском корпусе всегда будут лучше исключительно русскоязычного корпуса. Однако для специфических задач по работе в русскоязычной среде они будут ничем не хуже», – уверен он.
Уже сейчас компании OpenAI, Google, Meta* и другие крупные разработчики самостоятельно составляют корпусы текстов для обучения своих моделей, специально задействуя профильных экспертов.
Бизнес привлекает специалистов по контенту, например копирайтеров и редакторов, для создания и проверки текстов, которые затем используются для обучения нейромоделей, рассказал RSpectr директор по продуктовому развитию ИИ Холдинга Т1 Сергей Карпович.
Он отметил, что
сейчас большое внимание уделяется развитию синтетических данных, которые впоследствии будут использоваться в моделях
КАЧЕСТВЕННАЯ «СИНТЕТИКА»
Комиссия по защите персональных данных Сингапура (Personal Data Protection Commission) провела исследование на тему синтетических данных. Под ними подразумевается информация, которая сгенерирована с использованием специально созданной математической модели.
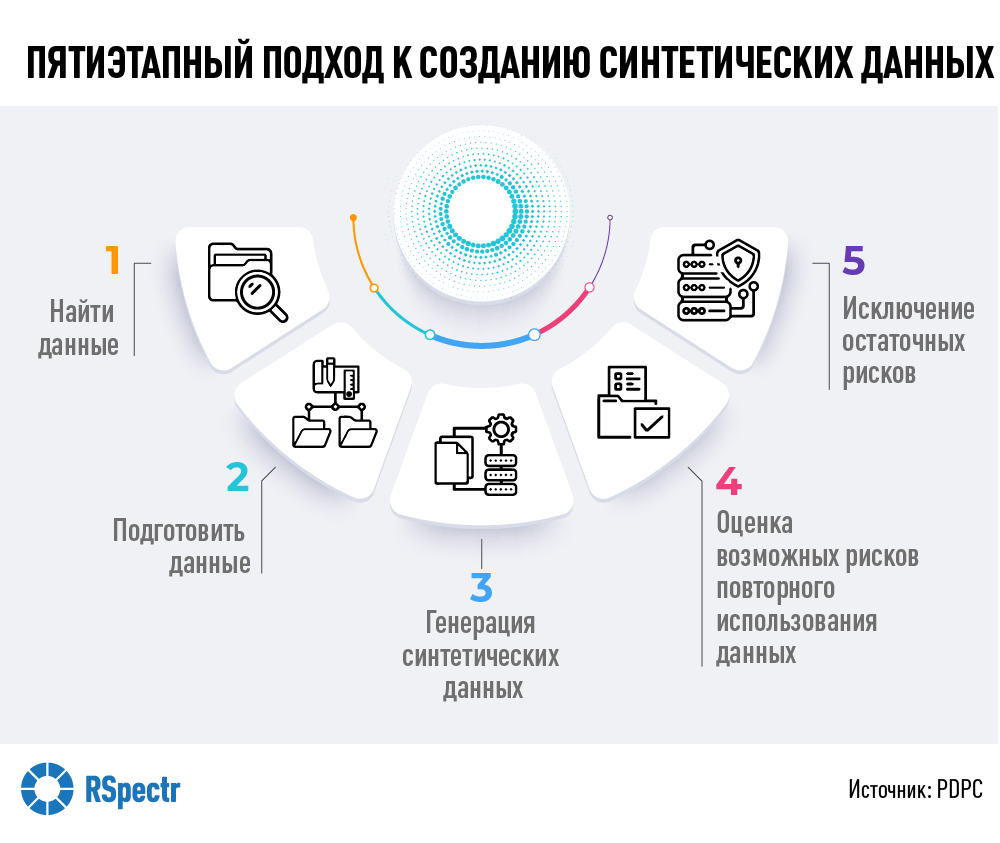
Помогут ли искусственные данные в деле совершенствования моделей? Эксперты не имеют однозначного мнения насчет полезности такого рода информации.
Сергей Карпович, Холдинг Т1:
– В условиях нехватки органического контента синтетическая генерация данных становится логичным выходом. Если раньше такие массивы считались неподходящими для алгоритмов, то с развитием генеративных моделей ситуация меняется: качество данных растет, они все чаще используются в процессах машинного обучения.
Синтетические данные в качестве моделей могут внести совсем немного нового, и для решения этой проблемы можно применять умершие языки и изобретение новых, решения для генерации кода на языке Фортран, полагает Алексей Нейман. Он добавил, что
«синтетика» может помочь только с узкоспециализированными задачами, в которых реальных данных (открытых текстов) слишком мало
Однако не все эксперты уверены в пользе синтетических данных. Нужно искать другие способы решения проблемы с дефицитом качественных данных, полагают они.
Дмитрий Демидов считает, что использование «синтетики» –
это повторное использование уже – переработанной информации. Полезных знаний у моделей от этого не добавится
Александр Бирюков, МГУ имени М.В. Ломоносова:
– Создание синтетических данных послужит лишь дополнительным механизмом для совершенствования ИИ-моделей. Оно поможет преодолеть препятствия в случае возникновения проблем с законодательством в сфере защиты персональных данных или в области авторского права.
НОВЫЕ ПУТИ
Если дефицит качественного контента все-таки возникнет, то необходимо искать альтернативы. Существуют ли иные механизмы совершенствования нейросетей, которые будут так же эффективно работать?
Алексей Нейман, АБД:
– Дальнейшему совершенствованию нейросетей могут послужить развитие механизма внимания в трансформерах*, новые архитектуры нейросетей, подходы к обучению и виды процессоров, а также рост производительности графического процессора GPU и обработка языка в любых формах: текст, изображение, звук.
В АНО «Цифровая экономика» считают, что
основной фактор, который сейчас влияет на качество моделей, – это не объемы данных, а объемы вычислительных мощностей
Александр Бирюков напомнил о перспективах квантового ИИ.
Александр Бирюков, МГУ имени М.В. Ломоносова:
– Существующие алгоритмы не подходят для использования на квантовом компьютере в силу фундаментальных различий в принципах работы железа, на котором работает программа. Новые алгоритмы ускорят обучение на несколько порядков, а также могут позволить гораздо более эффективно извлекать информацию из имеющихся данных.
По мнению, Григория Шершукова из «Наносемантики»,
новым этапом станет использование гибридных моделей
Комбинирование различных типов моделей, таких как нейронные сети и традиционные алгоритмы машинного обучения, может привести к созданию более гибких и мощных решений. Применение данных и подходов из разных областей науки и техники, таких как лингвистика, когнитивные науки и информатика, может привести к созданию более интеллектуальных и способных моделей, пояснил эксперт.
* Вид нейросетевой архитектуры, который хорошо подходит для обработки последовательностей данных.
Анастасия Солянина
















